From junior engineers to veterans — here's why they subscribe.
18,945subscribers
200+deep-dive articles
4 toolshands-on practice
"You have an amazing Substack, full of in-depth knowledge. I've been doing data for decades, and I still learn new things from you. Keep up the good work."
— Veteran Data Engineer, US
"I've been reading your writings for a while, and I really appreciate the level of depth you are exploring. On top of that the illustrations are top notch and support a visual understanding of the tech behind."
— Data Engineer, Europe
"We're building out our company's first data lakehouse and we're a team of mostly juniors. Your writing and insight has so far been invaluable, and I hope we can use what we learn from your articles to steward a better culture of data at the org!"
— Data Engineer, US
"I love your articles about DE that go deep, like I've never seen before from other people."
— Data Engineer
"You break things down to the level that I find easy to comprehend. You deserve to be paid for your content. You help me in my professional life."
— Software Engineer
"I'm practically using your articles as a roadmap to become a better data engineer."
— Data Engineer, Malaysia
The tools
Hands-on tools.
Right on your laptop or in your browser. Like playing a game: read, code, verify, move on.
A web-based app that lets you practice both Spark SQL and the DataFrame API without any setup — helping you prepare for interviews and sharpen your Spark skills at your own pace.
👉 You can visit spark.vutrinh.net to try the first 5 problems — no sign-up required.
💡 Already a paid member or just joined? Visit spark.vutrinh.net and sign up with your Substack email to unlock all problems.
65exercises
0setup needed
self-pacedto complete
Learn every crucial Apache Spark internal concept — from RDD basics and transformations to aggregations and joins.
32exercises
<15mto install
2h+to complete
Learn dbt from the ground up — models, tests, sources, macros and more, through hands-on exercises.
49exercises
<15mto install
3h+to complete
Learn Apache Airflow from the ground up — DAGs, operators, hooks, sensors, and more, through hands-on exercises.
A taste of what's inside — sharp, technical, no fluff.
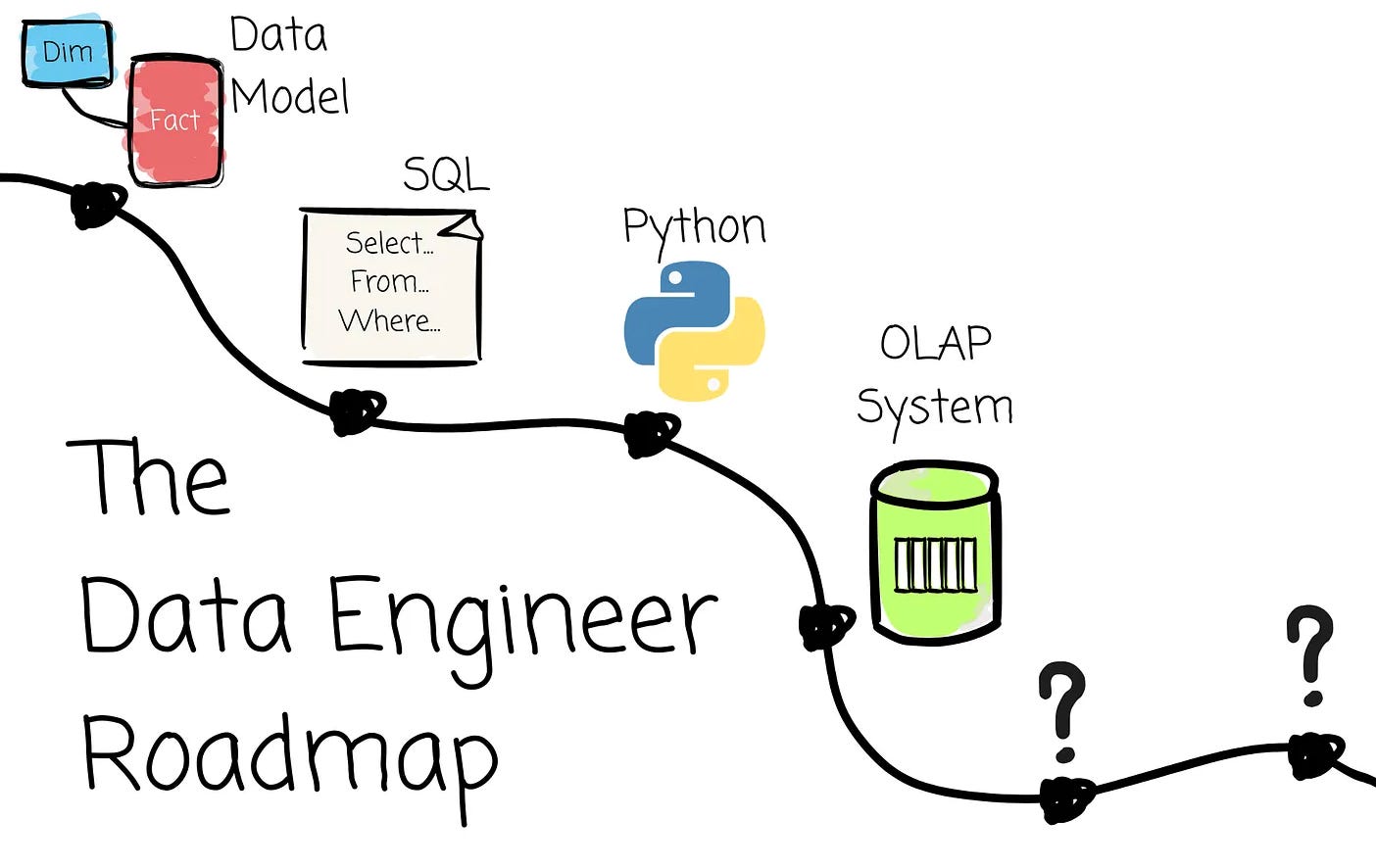
The skills a data engineer should learn — in order. From Data Modeling and SQL, through OLAP systems, dbt, and data formats, to processing engines, orchestration, Kafka, and stream processing. A practical roadmap built from real experience.
A completely new user would be overwhelmed by the diversity of cloud services. If you're a data engineer already overwhelmed by everything to learn, entering the Cloud without prior experience would leave you 2x as overwhelmed. Here's a vendor-agnostic guide to start.